数据科学的三驾马车 浅析数据分析、机器学习与数据挖掘的异同
在当今大数据时代,数据处理、数据分析、数据挖掘和机器学习等术语频繁出现,它们常常被混用,但其核心内涵与侧重点各有不同。本文将为您梳理这几个概念之间的关系与区别,特别是探讨数据分析与机器学习是否等同于数据挖掘,以及数据处理在其中扮演的基础角色。
核心概念辨析
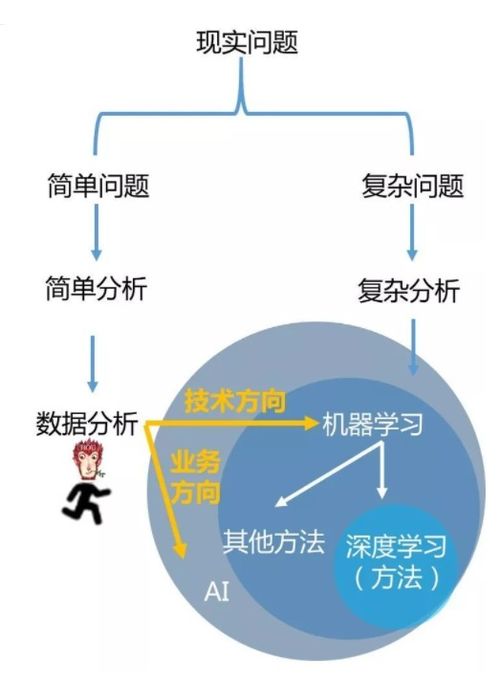
我们可以将这几个概念视为一个从基础到高级、从广泛到具体的连续光谱。
1. 数据处理 (Data Processing)
这是整个流程的基石。数据处理指的是对原始数据进行收集、清洗、转换、整合和存储等一系列操作,使其变得规整、可用。它关注的是数据的“形态”和“质量”,目标是得到一个干净、结构化的数据集,为后续所有分析工作做好准备。没有有效的数据处理,任何高级分析都如同空中楼阁。
2. 数据分析 (Data Analysis)
这是一个更为宽泛的上层概念。数据分析旨在通过统计方法、可视化工具和业务逻辑,对数据进行探索、解释,以发现趋势、模式和洞察,从而回答具体的业务问题或支持决策。其核心是“解释过去”和“理解现状”。例如,分析上季度的销售数据以找出哪个产品最受欢迎。
3. 数据挖掘 (Data Mining)
数据挖掘可以看作是数据分析的一个特定子集或高级阶段。它更侧重于从大型数据集中自动或半自动地发现先前未知的、有效的、潜在有用的模式(如关联规则、聚类、异常点)。数据挖掘更像是“勘探”过程,使用统计、机器学习等多种技术,在数据中“挖掘”出隐藏的知识。其目标往往是预测性的或描述性的。
4. 机器学习 (Machine Learning)
机器学习是实现数据挖掘(以及更广泛的数据分析)的一种核心技术手段和工具集。它专注于开发算法和模型,让计算机能够从数据中“学习”规律,并利用这些规律对新数据进行预测或决策。机器学习模型(如分类、回归、聚类算法)是执行数据挖掘任务(如客户分群、销量预测)的引擎。
关系与区别
现在,我们可以直接回答核心问题:数据分析和机器学习一样吗?它们和数据挖掘又是什么关系?
答案是否定的,它们并不等同,而是相互交织、各有侧重的概念。
- 数据分析 vs. 数据挖掘:数据分析范围更广,包含了描述性、诊断性分析;而数据挖掘特指通过算法探索数据中隐藏模式的过程,更偏向于预测性和发现性。可以说,数据挖掘是数据分析中技术性更强、更自动化的一个分支。
- 数据分析/数据挖掘 vs. 机器学习:这是目的与手段的关系。数据分析和数据挖掘是目标领域——我们想通过数据达成什么(洞察、预测、发现模式)。机器学习是实现这些目标的主要技术方法之一(其他方法还包括传统统计等)。例如,我们利用“机器学习”算法(手段)来“挖掘”客户流失的预测模型(数据挖掘任务),最终形成“数据分析”报告以指导业务行动。
数据处理:不可或缺的基础
在整个链条中,数据处理是所有这些活动的前置条件和公共基础。无论是进行简单的业务数据分析,还是构建复杂的机器学习模型,第一步永远是获取和处理好数据。高质量的数据处理能极大提升后续分析和挖掘的效率和准确性。
与比喻
用一个简单的比喻来概括:
- 数据处理好比是淘金前的筛选和清洗矿石的过程。
- 数据分析是研究这些矿石的成分、价值并出具报告的整个工作。
- 数据挖掘是报告中特别专注于利用特定工具深入矿脉,寻找未知金矿藏的章节。
- 机器学习则是用来寻找矿藏的最先进的探测仪和自动化挖掘设备。
因此,它们是紧密相连但又层次分明的概念。在实际的数据科学项目中,这些环节往往形成一个闭环迭代的流程:从数据处理开始,经过分析与挖掘(运用机器学习等方法),产生的洞察又可能指导新一轮的数据收集与处理。理解它们的区别与联系,有助于我们更清晰地规划项目、选择工具并有效地从数据中创造价值。
如若转载,请注明出处:http://www.zzzcvip.com/product/79.html
更新时间:2026-04-14 17:06:23